6. D'où viennent les chiffres macro ? Sources, fréquence et fiabilité
· 29 min de lecture
Un matin de milieu de mois, 14 h 29 à Paris, 8 h 29 à Washington. Dans les salles de marché, les conversations s'éteignent une à une ; les traders ont les yeux sur l'horloge, les algorithmes sont armés, et plus personne ne touche à rien. À 8 h 30 précises, heure de la côte Est, le Bureau of Labor Statistics publiera l'inflation américaine du mois écoulé. À 8 h 30 et une fraction de seconde, des machines auront lu le chiffre, l'auront comparé au consensus, et des dizaines de milliards de dollars auront changé de mains — avant même qu'un humain ait fini de lire le titre. Actions, obligations, devises : toute la fraction du premier chapitre, revenus futurs au numérateur et taux d'actualisation au dénominateur, vient de se recalculer autour d'un nombre à un chiffre après la virgule.
Arrêtons l'image, et retournons-la. D'où sort-il, ce nombre qui suspend la respiration des marchés ? D'un institut de statistique — c'est-à-dire de fonctionnaires, d'enquêteurs, de questionnaires et de programmes informatiques qui, pendant des semaines, ont relevé des dizaines de milliers de prix dans des magasins, des stations-service et des sites marchands, les ont agrégés, corrigés, pondérés, puis gardés sous scellés jusqu'à la seconde de l'embargo. Le chiffre le plus attendu de la planète financière n'est pas une lecture de la réalité : c'est un produit manufacturé. Et comme tout produit, il a des matières premières, une chaîne de fabrication, des délais de livraison, des défauts de série — et un service après-vente qu'on appelle les révisions.
Le chapitre précédent s'est achevé sur une promesse : après le vocabulaire, l'envers de la cuisine statistique — sans lequel le meilleur lexique du monde ne ferait que commenter des nombres en carton. Nous y sommes. Ce chapitre répond à cinq questions que tout investisseur devrait se poser une fois dans sa vie, puis ne plus jamais oublier : qui fabrique les chiffres macroéconomiques ? À partir de quoi ? À quel rythme tombent-ils ? Pourquoi changent-ils après coup ? Et jusqu'où peut-on s'y fier — quand l'erreur est honnête, et quand elle ne l'est pas ?
La réponse courte, que les pages qui suivent vont déplier : les chiffres macro sont des estimations — datées, échantillonnées, révisables —, produites par des institutions dont l'indépendance est un bien fragile, et livrées selon un calendrier si régulier qu'il rythme la vie des marchés comme une liturgie. Les respecter sans les vénérer, les utiliser sans les prendre pour la réalité elle-même : c'est toute la compétence que ce chapitre veut installer.
Des chiffres fabriqués, au sens noble du terme
Commençons par une évidence qui n'en est pas une : le PIB n'existe pas dans la nature. Personne n'a jamais vu un produit intérieur brut, ni croisé un taux de chômage dans la rue. Ces grandeurs sont des constructions statistiques : des conventions qui définissent un concept — qu'est-ce que « produire » ? qu'est-ce que « chercher un emploi » ? —, puis des dispositifs de mesure qui tentent de l'approcher. La nuance n'a rien de philosophique. Elle rappelle qu'entre la réalité économique et le chiffre qui la résume s'intercalent des choix humains : ce qu'on compte, ce qu'on ignore, comment on interroge, comment on corrige.
Ces constructions ont d'ailleurs une date de naissance, étonnamment récente. Au début des années 1930, en pleine Grande Dépression, le gouvernement américain pilotait à l'aveugle : les soupes populaires s'allongeaient, mais aucune mesure d'ensemble de l'activité n'existait. Le Congrès commanda alors à l'économiste Simon Kuznets la première comptabilité du revenu national ; son rapport de 1934 fonda ce qui deviendrait le PIB, et la guerre — où il fallut planifier la production d'un continent — en fit un outil d'État. En Grande-Bretagne, Richard Stone bâtissait au même moment la norme internationale des comptes nationaux, ce langage commun qui permet de comparer le PIB du Japon à celui du Brésil ; l'un et l'autre reçurent le prix Nobel. Détail instructif : dès 1934, Kuznets mettait le Congrès en garde — le bien-être d'une nation, écrivait-il en substance, ne peut guère se déduire d'une mesure du revenu national. Le père du PIB fut le premier à en borner le sens.
Il en découle une conséquence que la profession a longtemps préféré taire : une mesure construite sur des enquêtes et des conventions porte une marge d'erreur, comme une mesure de physique — or les chiffres économiques sont publiés, commentés et tradés comme des vérités à la décimale près. L'économiste Oskar Morgenstern en avait fait un livre classique, On the Accuracy of Economic Observations : aucun physicien ne publierait une constante sans son intervalle d'incertitude, notait-il en substance, mais des économies entières se pilotent sur des nombres dont personne n'affiche l'à-peu-près. Retenez le renversement : ce n'est pas parce qu'un chiffre est officiel qu'il est exact ; c'est parce qu'il est officiel qu'il est utilisable — défini publiquement, produit méthodiquement, corrigé honnêtement. L'exactitude, elle, viendra par approximations successives.
Qui fabrique quoi : la carte des producteurs
Premier repère : dans la plupart des pays, la statistique publique est l'affaire d'un institut national de statistique — l'INSEE en France, Destatis en Allemagne, l'ONS au Royaume-Uni —, flanqué d'un office européen, Eurostat, qui harmonise les méthodes et agrège les chiffres de la zone euro. Les États-Unis, eux, ont un système décentralisé qui déroute au début : le Bureau of Labor Statistics (BLS) produit l'emploi et les prix à la consommation ; le Bureau of Economic Analysis (BEA) produit le PIB et l'inflation PCE ; le Census Bureau produit les ventes au détail, le logement, le commerce extérieur. Trois logos différents pour trois morceaux du même tableau de bord — d'où l'utilité, pour l'investisseur, de savoir qui publie quoi : cela dit à quelle porte frapper pour lire la méthode, et quel communiqué guetter à quelle date.
Deuxième famille : les banques centrales, consommatrices voraces et productrices à la fois — la Réserve fédérale publie la production industrielle et les comptes financiers, la BCE les statistiques monétaires et bancaires de la zone euro. Troisième famille, les organisations internationales — FMI, OCDE, Banque mondiale, BRI — qui collectent peu mais harmonisent et comparent, et surtout fixent des normes de qualité et de diffusion auxquelles les États acceptent de se soumettre.
Reste une quatrième famille, souvent sous-estimée : les producteurs privés. L'ISM américain interroge les directeurs d'achats de l'industrie depuis les années 1930 ; S&P Global publie ses PMI dans des dizaines de pays ; le Conference Board et l'université du Michigan — celle-ci depuis 1946 — sondent le moral des ménages. Ces enquêtes ne mesurent pas l'activité mais des réponses — un jugement, une intention. C'est la grande partition du tableau de bord, déjà croisée dans le panorama : données molles (les enquêtes d'opinion) contre données dures (l'activité réalisée). Les premières arrivent tôt et se trompent d'humeur ; les secondes arrivent tard et se trompent de peu. L'investisseur utilise les deux, en sachant toujours laquelle il lit.
Un mot, enfin, sur ce qui fait tenir l'ensemble : la déontologie statistique. Depuis 1994, des principes fondamentaux adoptés à l'ONU posent que la statistique officielle se produit selon des critères strictement professionnels — méthodes publiques, calendriers annoncés à l'avance, données accessibles à tous au même instant, indépendance vis-à-vis du pouvoir politique. Cette indépendance n'est pas un ornement : c'est elle qui fait qu'un marché peut trader un chiffre officiel et qu'un citoyen peut demander des comptes. Nous verrons en fin de chapitre ce qui arrive quand elle cède.
La recette : sondages géants, registres et caisses enregistreuses
Comment fabrique-t-on un chiffre macro ? Avec trois matières premières, qui se complètent parce qu'aucune ne suffit.
La première, la plus noble et la plus fragile : l'enquête. L'inflation américaine repose sur quelque 80 000 prix relevés chaque mois par des enquêteurs, en magasin, par téléphone et en ligne. Le taux de chômage sort d'un sondage auprès d'environ 60 000 ménages — l'enquête ménages —, interrogés sur leur situation dans la semaine de référence. Les créations d'emplois sortent d'une tout autre source, l'enquête établissements, qui collecte les fiches de paie d'environ 120 000 employeurs. D'où une subtilité que le lecteur du rapport emploi découvre vite : le même communiqué contient deux enquêtes, aux périmètres différents, qui peuvent raconter deux histoires différentes le même mois — un taux de chômage qui monte pendant que les embauches accélèrent, ou l'inverse.
Or un sondage, même géant, reste un sondage. Interroger 60 000 ménages pour en déduire la situation de 170 millions d'actifs, c'est extrapoler ; extrapoler, c'est accepter une marge d'erreur. Le BLS la publie, à qui veut bien la lire : l'intervalle de confiance à 90 % sur les créations d'emplois mensuelles est de l'ordre de ± 130 000. Relisez ce nombre : quand le marché s'enflamme parce que « l'économie a créé 180 000 emplois au lieu des 150 000 attendus », l'écart célébré est inférieur au flou de la mesure. La précision affichée est une politesse, pas une réalité. Et cette fragilité s'aggrave : partout dans le monde, les taux de réponse aux enquêtes s'érodent — celui de l'enquête ménages américaine a glissé de plus de 90 % vers 70 % en une quinzaine d'années, certaines enquêtes auprès des entreprises tombant vers un tiers —, ce qui élargit les marges et complique les redressements. Une boutade centenaire, rapportée par l'économiste britannique Josiah Stamp en 1929, garde ici sa fraîcheur : les gouvernements adorent accumuler des statistiques, mais au bout de la chaîne, quelqu'un inscrit « ce que bon lui semble » dans la case du formulaire. Exagéré — les instituts recoupent et redressent —, mais l'exagération pointe juste : une statistique vaut ce que valent ses déclarants.
Deuxième matière première, symétrique de la première : le registre administratif — des données produites non pour mesurer, mais pour gérer. Les inscriptions hebdomadaires au chômage américaines ne sont pas un sondage : c'est le comptage, guichet par guichet, des demandes d'allocations réellement déposées. Les douanes enregistrent chaque conteneur ; le fisc voit passer salaires et chiffres d'affaires. Ces sources sont quasi exhaustives — pas d'échantillon, guère de marge d'erreur — mais étroites : elles ne voient que ce que l'administration gère (qui ne s'inscrit pas n'existe pas), avec ses définitions à elle, souvent avec retard. La statistique moderne marie donc les deux : l'enquête pour la rapidité et la finesse, le registre pour l'exactitude — le second servant, une fois l'an, à recaler la première ; ce recalage fera l'actualité plus bas.
Troisième matière première, la plus récente : la donnée massive. Depuis 2020, l'INSEE calcule une partie des prix français directement à partir des données de caisse des supermarchés — des millions de transactions réelles plutôt que des relevés d'enquêteurs. Deux chercheurs du MIT, Alberto Cavallo et Roberto Rigobon, avaient ouvert la voie dès 2008 avec le Billion Prices Project, qui aspirait chaque nuit les prix des sites marchands du monde entier — projet né, précisément, du soupçon pesant sur la statistique argentine, dont il démontra la manipulation en publiant chaque jour une inflation alternative. Cartes bancaires, offres d'emploi en ligne, images satellites : la panoplie s'élargit chaque année, en complément des enquêtes plus qu'en remplacement.
Reste la cuisine proprement dite, qui transforme la matière brute en chiffre publiable — le chapitre précédent en a donné les mots. On corrige des variations saisonnières, par des programmes que le monde entier emprunte au Census Bureau, pour que décembre ne ressemble pas mécaniquement à un boom du commerce. On annualise. On impute ce qui manque : l'enquête établissements ne voit pas les entreprises qui naissent et meurent dans le mois — un modèle statistique l'estime. On ajuste les prix des effets de qualité : si le nouveau téléphone coûte 5 % de plus mais fait deux fois mieux, quelle part est de l'inflation ? Chaque traitement est raisonnable, documenté — et faillible, surtout quand le monde sort de ses gonds. La pandémie en fit la démonstration : en avril 2020, l'Amérique détruisit plus de vingt millions d'emplois en un mois ; le taux de chômage bondit à 14,7 % — et le BLS précisa, dans le communiqué même, qu'une erreur de classement massive (des millions d'absents comptés « avec emploi » qui étaient en réalité licenciés temporaires) aurait dû le porter près de cinq points plus haut, vers 20 %. L'aveu, à chaud, dans le document officiel : voilà la différence entre une statistique honnête et une statistique exacte.
Le calendrier : le mois type de l'investisseur
Ces chiffres fabriqués, il faut maintenant les livrer — et c'est ici que la statistique rencontre la liturgie. Chaque grande publication a son jour, son heure, sa fréquence, annoncés des mois à l'avance dans des calendriers officiels. Les marchés vivent à ce rythme, au point que la volatilité d'une journée se prédit en partie à son menu statistique. Voici le mois américain type — celui qui donne le tempo mondial.
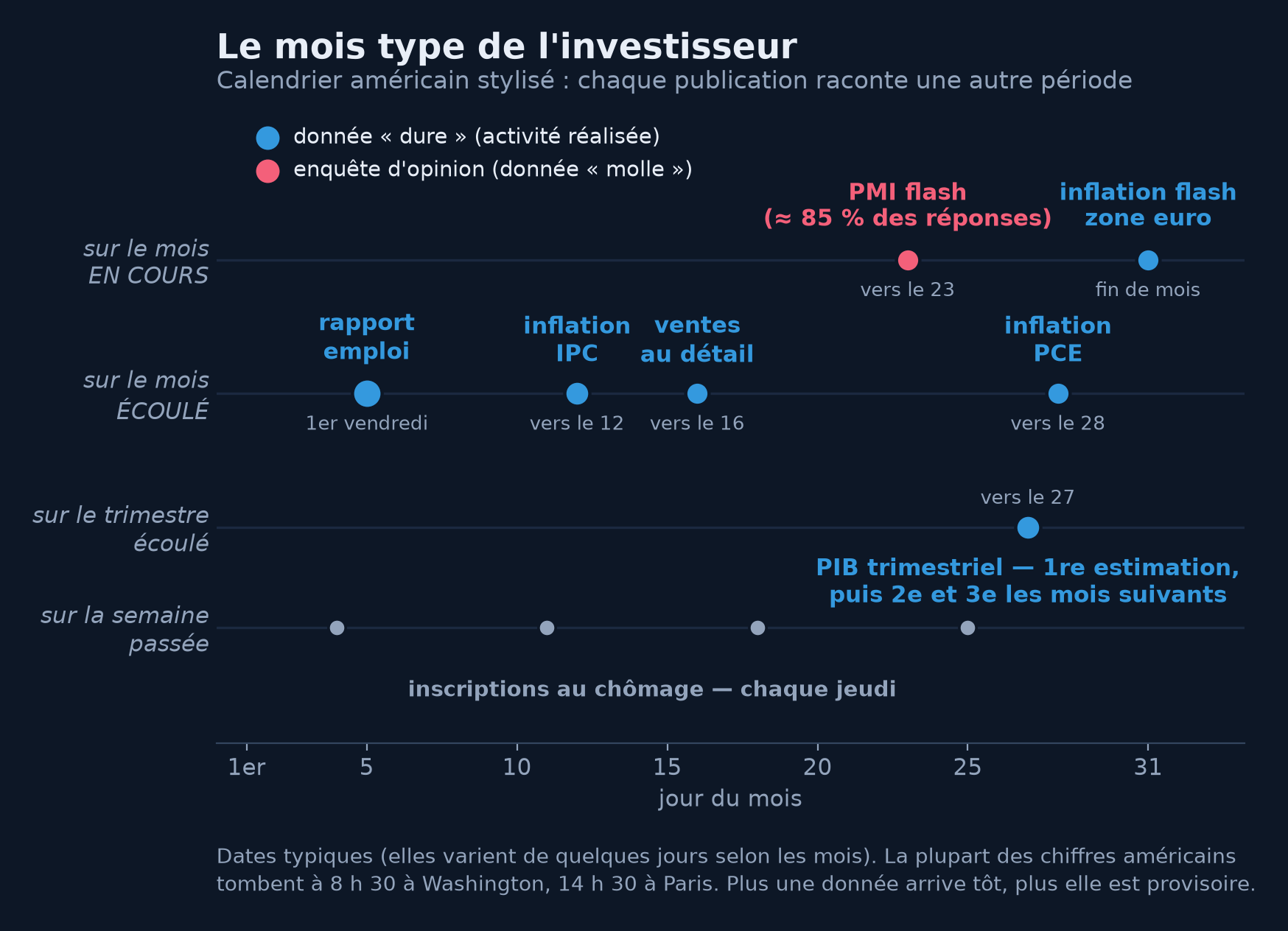
Le mois de l'investisseur, en un regard. Chaque pastille est un rendez-vous récurrent ; sa ligne indique la période qu'elle raconte. Les enquêtes (rouge) devancent toujours les données réalisées (bleu) — le PMI flash décrit un mois qui n'est pas fini, le PIB arrive un mois après le trimestre qu'il mesure.
Trois cadences s'emboîtent. L'hebdomadaire : chaque jeudi, les inscriptions au chômage de la semaine passée — le pouls le plus rapide de l'économie américaine, donnée administrative presque en temps réel. Le mensuel, l'ossature du calendrier : l'enquête ISM le premier jour ouvré, le rapport emploi le premier vendredi — le rendez-vous roi —, l'IPC vers le 12, les ventes au détail à la mi-mois, l'inflation PCE (celle que la Fed cible) en toute fin de mois. Le trimestriel, enfin : le PIB, publié environ un mois après la fin du trimestre — puis republié deux fois, on va y venir. L'Europe suit une partition voisine avec une originalité remarquable : l'estimation provisoire de l'inflation française et l'estimation flash de la zone euro tombent le dernier jour du mois qu'elles mesurent ou le lendemain — les États-Unis, eux, n'ont pas de flash : il faut attendre le rapport complet.
L'heure compte autant que le jour. La plupart des chiffres américains tombent à 8 h 30, heure de Washington — 14 h 30 à Paris —, selon un rituel réglé à la seconde : journalistes accrédités enfermés sous embargo, dépêches et serveurs officiels qui basculent au même instant. Cette simultanéité garantit qu'aucun acteur ne trade le chiffre avant les autres — condition pour que la surprise, l'écart au consensus, joue son rôle de choc pur, celui que le panorama a disséqué. Dans les premières millisecondes, ce sont les algorithmes qui lisent ; l'humain arbitre les secondes suivantes, la séance digère le reste.
Dernière clé de lecture du calendrier, la plus stratégique : la hiérarchie entre vitesse et solidité. Les enquêtes arrivent avant les données dures — le PMI flash paraît vers le 23 du mois qu'il décrit, sur environ 85 % des réponses attendues, soit une semaine avant que ce mois soit fini et des semaines avant la première donnée dure. Cette avance a un prix : elle mesure un ressenti. À l'autre bout, le PIB dit presque tout, presque définitivement — trois mois trop tard pour un trader. D'où le triangle qu'aucun chiffre ne résout : tôt, riche, définitif — il faut choisir deux qualités sur trois.
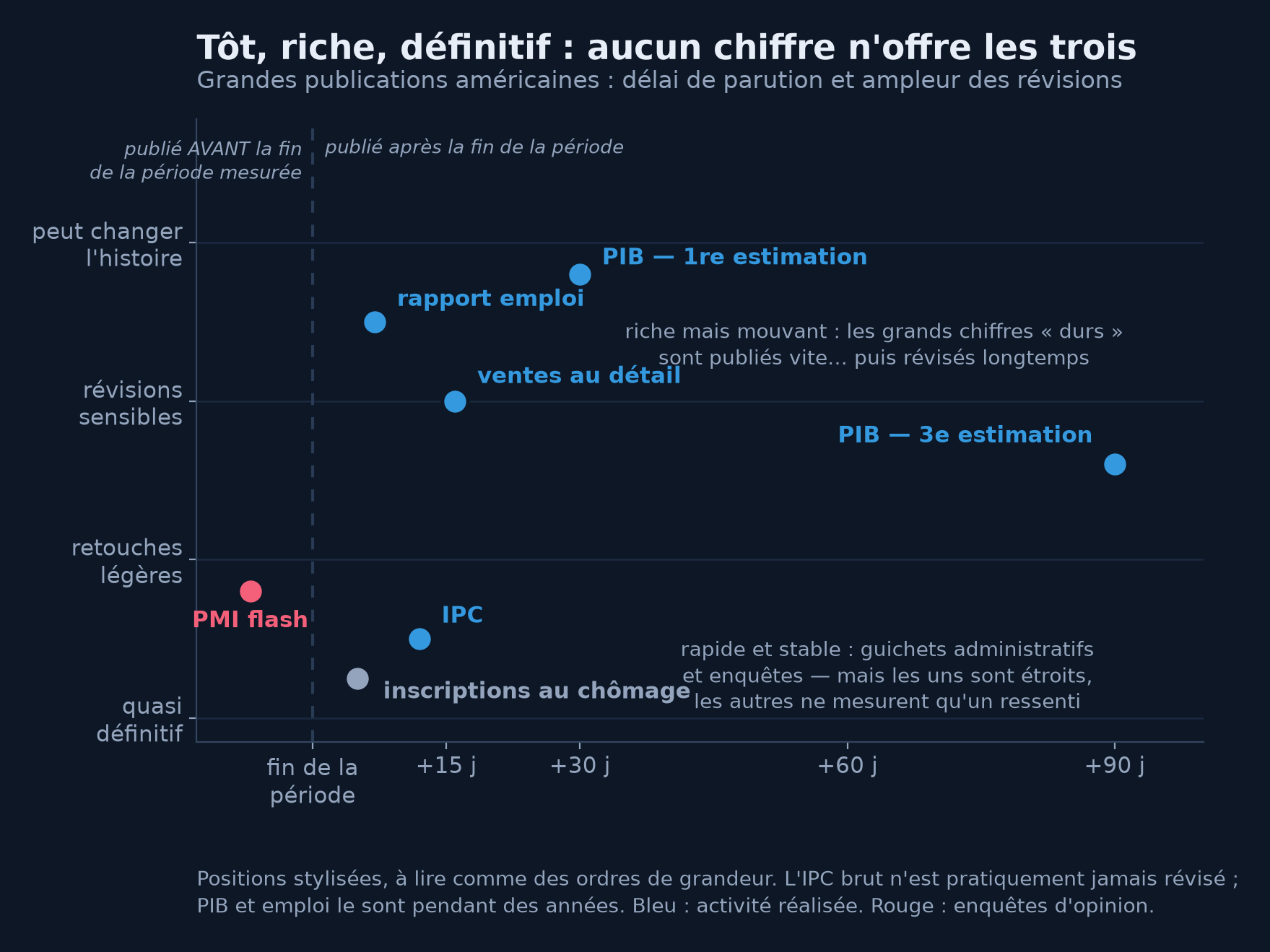
Le triangle impossible du chiffre macro. En bas à gauche, le rapide et stable : enquêtes d'opinion et guichets administratifs — mais les unes ne mesurent qu'une humeur, les autres un périmètre étroit. En haut, les grands chiffres durs : publiés vite pour leur richesse, puis révisés pendant des années. L'IPC est l'exception qui confirme la règle : publié à douze jours et pratiquement jamais retouché — c'est pour cela qu'on peut indexer des contrats dessus.
La vérité est provisoire : au royaume des révisions
Nous voici au fait le plus troublant de la statistique macro, déjà croisé deux fois sans le regarder en face : les chiffres changent après leur publication. Non par erreur au sens vulgaire, mais par construction. La première estimation est calculée avec les réponses arrivées à temps — une fraction de l'échantillon — et des hypothèses pour boucher les trous. Puis les retardataires répondent, les sources lentes (bilans, fisc, registres sociaux) deviennent disponibles, les coefficients saisonniers se recalculent — et l'estimation est révisée : une fois, deux fois, puis lors de campagnes annuelles et de refontes méthodologiques. Le PIB américain paraît ainsi en trois temps — estimation d'avance, deuxième, troisième, à un mois d'intervalle — avant d'être repris chaque automne, pendant des années. L'ampleur n'a rien d'anecdotique : d'après les études du BEA lui-même, la révision moyenne entre la première estimation d'un trimestre et sa valeur d'aujourd'hui est de l'ordre d'un bon point de croissance annualisée — quand la frontière entre « l'économie accélère » et « l'économie cale » se joue précisément à un point près.
Une image vaut mieux qu'un discours. Voici, sur données réelles millésimées, l'histoire des deux trimestres les plus commentés de notre fil rouge — ceux qui, à l'été 2022, ont mis « récession » à la une de tous les journaux.
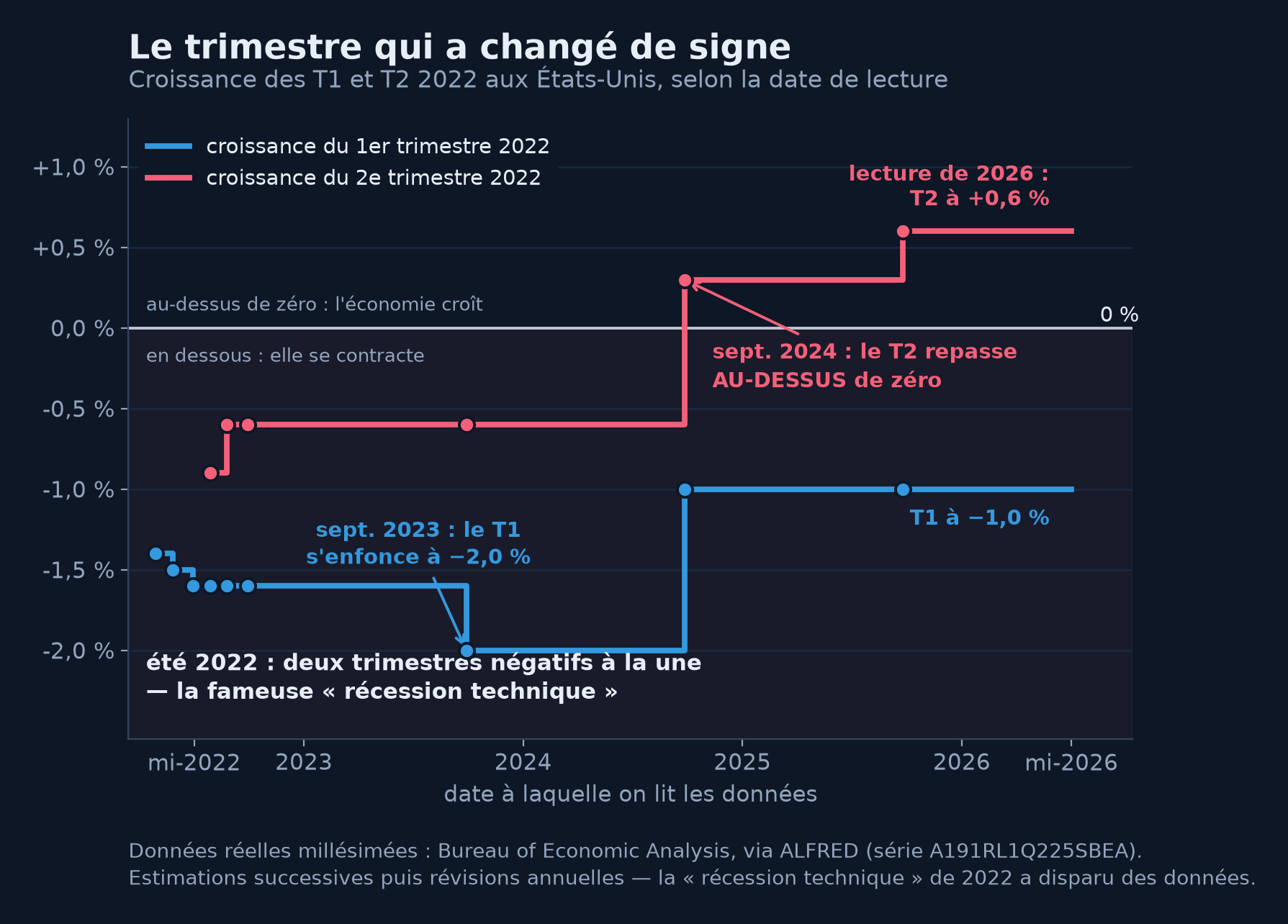
Le même semestre, lu à quatre ans d'écart. À l'été 2022, les données affichent deux trimestres consécutifs de recul (−1,6 % puis −0,9 % en première estimation) : récession technique, débat planétaire. Révision après révision, le deuxième trimestre remonte, passe en positif en septembre 2024, et s'établit à +0,6 % dans les données de 2026 : la récession technique de 2022 n'existe plus. Le NBER, lui, n'avait jamais déclaré de récession — l'emploi était trop solide.
La « récession technique fantôme » du chapitre précédent n'était donc pas qu'une affaire de définition — c'était aussi une affaire de millésime : éditorialistes, investisseurs et politiques ont débattu des mois durant d'un fait statistique qui, quelques campagnes de révisions plus tard, a cessé d'exister. Personne n'a menti ; chaque estimation était la meilleure possible avec l'information du moment. Mais l'histoire économique s'écrit au crayon, et il faut des années pour qu'elle passe à l'encre.
L'emploi américain vit la même vie, avec son propre vocabulaire. Chaque chiffre mensuel est révisé les deux mois suivants, à mesure que les réponses tardives arrivent. Puis, une fois l'an, l'enquête entière est recalée sur les registres quasi exhaustifs de l'assurance chômage — le registre corrigeant l'enquête, comme promis plus haut. Et ce recalage peut être brutal : en août 2024, le BLS annonça une estimation préliminaire de −818 000 emplois sur les douze mois achevés en mars 2024 — la plus forte correction depuis 2009 ; en septembre 2025, l'exercice suivant retrancha encore −911 000 emplois sur les douze mois achevés en mars 2025. Des centaines de milliers d'emplois, célébrés en direct chaque premier vendredi du mois, n'ont simplement jamais existé. Voici l'année 2024 racontée deux fois :
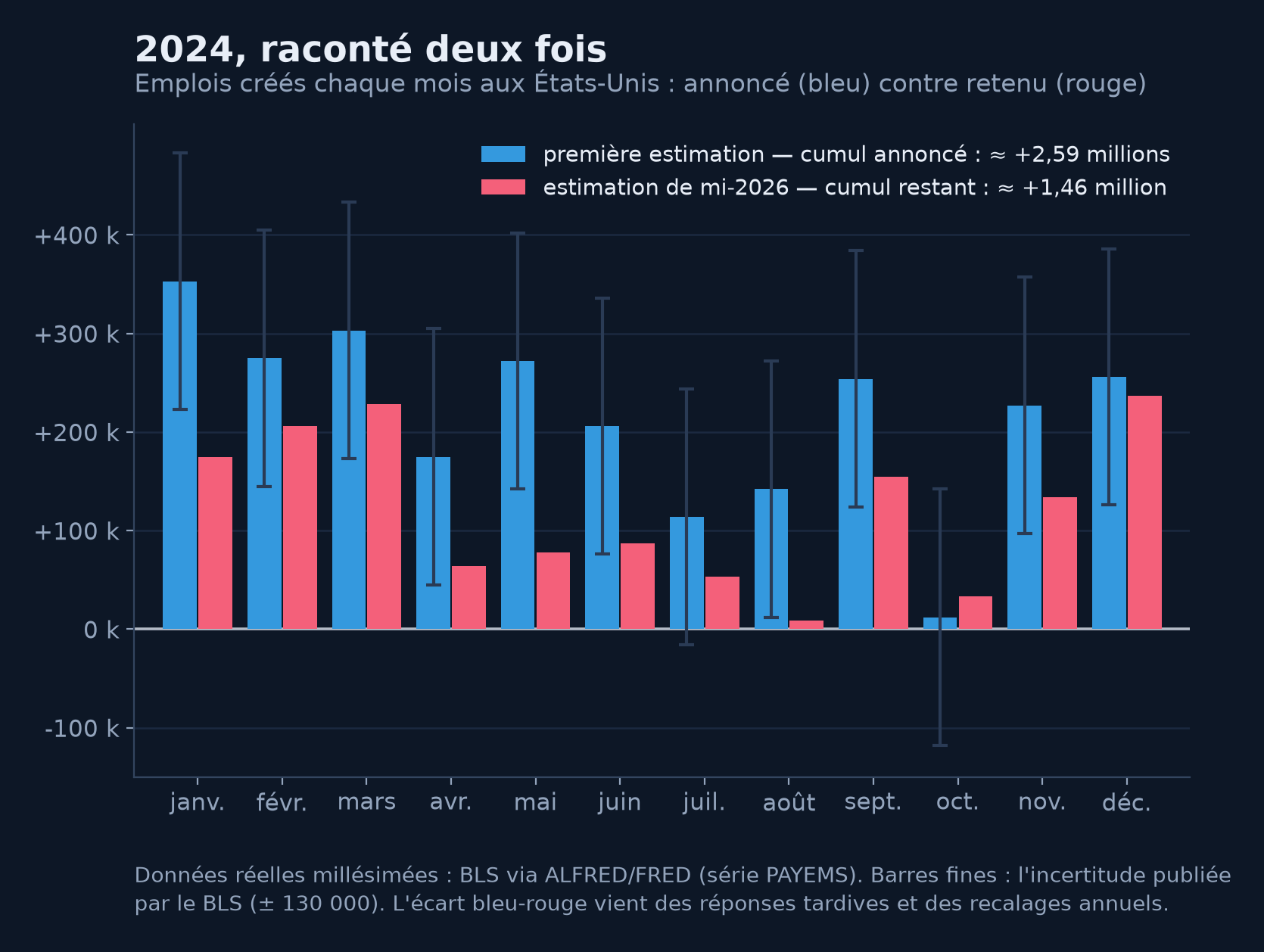
2024 telle qu'annoncée (bleu) et telle que les données la racontent aujourd'hui (rouge). Au fil des premiers vendredis du mois, les publications ont annoncé environ 2,6 millions d'emplois créés ; il en reste 1,5 million dans les données de mi-2026 — l'écart vient des réponses tardives et des recalages annuels sur les registres. Notez les barres d'erreur, publiées par le BLS et presque jamais citées : ± 130 000 sur chaque première estimation.
Le phénomène n'est pas américain : en 2023, l'office statistique britannique révisa sa mesure de la reprise post-COVID et découvrit que l'économie du royaume, donnée pour environ 1 % sous son niveau d'avant-pandémie fin 2021, se trouvait en réalité au-dessus — près de deux points de PIB retrouvés d'un trait de plume. Qu'en conclure ? D'abord, que les marchés tradent la première estimation : c'est elle qui porte la surprise, donc le mouvement — être démentie plus tard n'annule pas la séance. Ensuite, que les récits bâtis en temps réel (« l'économie est en récession », « l'emploi est en surchauffe ») reposent sur du provisoire : le faisceau d'indices — plusieurs indicateurs, plusieurs mois — est fiable là où le point isolé ne l'est pas. Enfin, le trou entre le trimestre qui s'écoule et son premier PIB a fait naître le nowcasting : le GDPNow de la Fed d'Atlanta, le plus suivi du genre, actualise ainsi depuis 2014 une estimation mécanique du trimestre en cours à chaque publication. Utile, à condition de le lire pour ce qu'il est — une estimation d'une estimation.
Un dernier piège, pour les lecteurs quantitatifs de ce site : celui du millésime en backtest. Tester une stratégie « qui achète quand les créations d'emplois dépassent 200 000 » sur les données actuelles, c'est utiliser des chiffres que personne ne connaissait à l'époque — les valeurs d'aujourd'hui incorporent des révisions arrivées des années plus tard. Ce biais d'anticipation embellit les backtests avec une constance perfide. La parade : les bases millésimées — ALFRED, l'archive de la Fed de Saint-Louis, conserve chaque état passé de chaque série, et c'est elle qui a fourni les figures de ce chapitre. Les modules de backtesting y reviendront ; plantons le réflexe : en recherche quantitative, on utilise les données telles qu'elles étaient, pas telles qu'elles sont devenues.
Jusqu'où s'y fier ? Erreurs honnêtes et chiffres sous influence
Tout ce qui précède décrit des erreurs honnêtes : échantillonnage, réponses tardives, conventions perfectibles. Il faut maintenant affronter la question de confiance dans toute son étendue — car entre l'imprécision de bonne foi et le mensonge d'État, il existe un continuum, et l'investisseur doit savoir où il se trouve sur la carte.
Côté bonne foi, d'abord, les débats de mesure — permanents, publics, parfois lourds de conséquences. Le plus célèbre : en 1996, la commission Boskin conclut que l'IPC américain surestimait l'inflation d'environ 1,1 point par an — biais de substitution, de qualité, de nouveaux produits —, verdict qui entraîna des réformes de méthode et pesa sur tout ce que l'IPC indexe, des retraites aux tranches d'impôt. Plus près de nous, le logement : il pèse environ un tiers de l'IPC américain, et sa méthode de mesure fait entrer les loyers dans l'indice avec un retard de l'ordre d'un an — pendant la poussée de 2021-2023, l'inflation officielle du logement a continué d'accélérer longtemps après le ralentissement des loyers de marché, posant une question très concrète : la Fed devait-elle piloter sur un thermomètre en retard ? Même les identités comptables ont leurs états d'âme : le revenu intérieur brut, qui devrait par construction égaler le PIB, s'en est sensiblement écarté en 2022-2023. Ajoutez la loi de Goodhart, énoncée en 1975 : toute régularité statistique tend à se dérégler dès qu'on s'en sert comme cible — résumée depuis en maxime : quand une mesure devient un objectif, elle cesse d'être une bonne mesure. Un chiffre que tout le monde surveille est un chiffre que tout le monde a intérêt à travailler.
Côté mauvaise foi, l'histoire récente offre trois cas d'école, gradués. Le cas grec, d'abord — celui qui a failli emporter une monnaie. Au printemps 2009, Athènes notifiait à Bruxelles un déficit prévu d'environ 3,7 % du PIB ; à l'automne, le gouvernement fraîchement élu révélait que le vrai chiffre serait plutôt 12,7 % ; après enquêtes d'Eurostat, l'histoire s'arrêta à 15,4 %. Ce n'était pas une révision, c'était un maquillage au long cours — et cette étincelle statistique alluma la crise de la zone euro, étude de cas qui attend ce parcours. L'Europe en tira la leçon : depuis 2010, Eurostat dispose de vrais pouvoirs d'audit sur les comptes nationaux. Le cas argentin, ensuite — la manipulation assumée : à partir de 2007, le gouvernement mit au pas son institut pour minorer l'inflation publiée, infligea des amendes aux économistes privés qui publiaient leurs propres mesures, et récolta en février 2013 une motion de censure du FMI — la première de l'histoire de l'institution pour données mensongères —, levée fin 2016 seulement. L'épisode fit éclore la mesure par les prix en ligne, et fixa le tarif de la fraude : un pays dont les chiffres mentent emprunte plus cher, car le doute est une prime de risque. Le cas chinois, enfin — le doute structurel : en 2007, le futur Premier ministre Li Keqiang confiait à l'ambassadeur américain, selon un câble révélé par WikiLeaks, que le PIB de sa province était « fabriqué par l'homme », et qu'il lui préférait trois séries difficiles à maquiller — électricité consommée, fret ferroviaire, crédits bancaires. Les marchés en firent un indice, et la méthode une leçon : quand le thermomètre officiel est suspect, on recoupe par des grandeurs physiques que personne ne pense à truquer.
On aurait tort, cependant, de ranger ces histoires dans le tiroir des pays lointains. L'indépendance statistique s'est rappelée récemment au souvenir de la première puissance mondiale, en plein cœur de notre fil rouge élargi : à l'été 2025, un rapport emploi décevant, assorti de fortes révisions baissières sur les mois précédents, fut suivi le jour même du limogeage de la directrice du BLS par le président américain, qui l'accusa sans preuve de truquer les chiffres ; à l'automne, un blocage budgétaire record suspendit des semaines durant les publications fédérales — laissant marchés et banque centrale piloter dans le brouillard, et privant définitivement les séries de certaines observations d'octobre. Quelles que soient les suites, la leçon d'investisseur est déjà acquise : la crédibilité d'une statistique nationale est une infrastructure publique, au même titre qu'un réseau électrique — invisible tant qu'elle fonctionne, hors de prix à reconstruire, et son érosion se paie en prime de risque.
D'où le verdict d'ensemble, qu'il faut tenir des deux mains. Oui, les chiffres des grandes démocraties statistiques sont fiables — non parce qu'ils seraient exacts, mais parce que leurs défauts sont publics : méthodes documentées, marges d'erreur publiées, révisions assumées et étudiées par les instituts eux-mêmes, normes internationales de diffusion (le FMI en tient une depuis 1996) auxquelles les États se soumettent volontairement. La transparence sur l'imperfection est précisément ce qui distingue la statistique de la propagande. Le jour où un institut cesse de réviser ses chiffres, ne publie plus ses méthodes ou fait taire ses contradicteurs — c'est ce jour-là qu'il faut s'inquiéter.
La boîte à outils : trouver les chiffres, et les lire sans se faire piéger
Reste le plus concret : où trouver tout cela ? Bonne nouvelle : l'essentiel est gratuit, et souvent meilleur que les services payants. La porte d'entrée universelle s'appelle FRED — la base de la Fed de Saint-Louis, des centaines de milliers de séries traçables et exportables en deux clics ; sa sœur ALFRED conserve les millésimes ; Eurostat, la BCE et l'INSEE offrent l'équivalent européen. Pour le rythme, un calendrier économique — tout grand portail financier en propose — affiche date, heure, consensus et valeur précédente de chaque publication : l'outil qui transforme le flot des dépêches en agenda lisible. Pour la méthode, la source primaire est imbattable : chaque communiqué du BLS ou du BEA contient ses notes techniques et ses marges d'erreur — et l'atelier du prochain module vous fera précisément ouvrir FRED et tracer vos premières séries.
Quant à la lecture, tout ce chapitre se condense en six réflexes, qui prolongent ceux du lexique. Un : identifiez ce que vous lisez — niveau ou variation, brut ou corrigé des variations saisonnières, glissement annuel ou rythme annualisé. Deux : comparez au consensus, jamais à zéro ni au mois précédent seul — c'est la surprise qui meut les marchés, leçon du panorama. Trois : respectez la marge d'erreur — un chiffre isolé est du bruit ; la moyenne de trois mois, un début de signal ; six mois cohérents, une tendance. Quatre : rappelez-vous que la première estimation sera révisée — ne bâtissez jamais une conviction définitive sur un chiffre provisoire, et méfiez-vous des récits qui le font. Cinq : croisez le mou et le dur — une enquête qui plonge sans que les données réalisées suivent est une humeur, pas encore un fait ; l'inverse est un fait qui n'a pas encore trouvé son récit. Six : en recherche quantitative, utilisez les données de l'époque, pas celles d'aujourd'hui.
À retenir — Un chiffre macro n'est pas un fait de nature : c'est une estimation manufacturée — échantillonnée, corrigée, désaisonnalisée — publiée selon un calendrier rituel et révisée pendant des années. Sa première version est celle qui fait bouger les marchés (parce qu'elle porte la surprise face au consensus) ; sa version finale est celle qui écrit l'histoire — et les deux peuvent différer du tout au tout, comme la « récession » américaine de 2022, disparue des données au fil des révisions. La marge d'erreur existe, publiée et ignorée : ± 130 000 sur les créations d'emplois américaines d'un mois. La fiabilité, elle, se juge à la transparence : méthodes publiques, révisions assumées, institut indépendant. Traitez chaque publication comme un témoignage sous serment — précieux, daté, faillible —, jamais comme un verdict.
La suite du voyage
Ce chapitre clôt l'inventaire des fondations : vous savez désormais pourquoi la macroéconomie pilote vos placements, à quelle échelle elle raisonne, quelles variables peuplent son tableau de bord, comment se parle sa langue — et d'où sortent ses chiffres, avec leurs forces et leurs à-peu-près. Il reste à transformer ce savoir en habitude. Ce sera l'objet du prochain chapitre, « Module 1 en pratique : se bâtir une routine de veille macro » : choisir ses quelques rendez-vous, ses quelques sources, son rituel de vingt minutes — et faire de tout ce qui précède non plus une lecture, mais un réflexe hebdomadaire. D'ici là, gardez la règle que ce chapitre voulait graver : derrière chaque chiffre macro, demandez-vous qui l'a fabriqué, à partir de quoi, s'il sera révisé — et lisez l'écart au consensus avant le chiffre lui-même.
Sources et références
- Simon Kuznets, National Income, 1929-1932, rapport au Sénat des États-Unis (1934) — l'acte de naissance de la comptabilité nationale américaine, et l'avertissement fondateur : le bien-être d'une nation ne peut guère se déduire d'une mesure du revenu national.
- Oskar Morgenstern, On the Accuracy of Economic Observations (Princeton University Press, 2e éd. 1963) — le livre classique sur les marges d'erreur des statistiques économiques, publiées sans leurs intervalles d'incertitude.
- Josiah Stamp, Some Economic Factors in Modern Life (1929) — la boutade du « veilleur de village » qui inscrit ce que bon lui semble, sur la fragilité des chaînes de collecte.
- Bureau of Labor Statistics, The Employment Situation — notes techniques : tailles d'échantillon des enquêtes ménages et établissements, intervalle de confiance à 90 % sur la variation mensuelle de l'emploi (± 130 000 dans les notes de 2024, ± 122 000 dans les plus récentes) ; communiqué d'avril 2020 (publié le 8 mai 2020) documentant l'erreur de classement pandémique (~5 points de chômage).
- Bureau of Labor Statistics, annonces préliminaires de recalage annuel de l'enquête établissements : −818 000 emplois (août 2024, douze mois achevés en mars 2024), −911 000 emplois (septembre 2025, douze mois achevés en mars 2025).
- Dennis Fixler, Ryan Greenaway-McGrevy & Bruce Grimm, « The Revisions to GDP, GDI, and Their Major Components », Survey of Current Business (BEA, août 2014) — l'étude de référence sur l'ampleur des révisions du PIB américain.
- Commission Boskin (Advisory Commission to Study the Consumer Price Index), Toward a More Accurate Measure of the Cost of Living (1996) — la surestimation de l'inflation américaine évaluée à environ 1,1 point par an.
- Charles Goodhart, « Problems of Monetary Management: The U.K. Experience » (1975) — la formulation originelle de la loi de Goodhart.
- Eurostat, Report on Greek Government Deficit and Debt Statistics (janvier 2010) — le constat officiel des falsifications grecques ; déficit 2009 finalement établi à 15,4 % du PIB (novembre 2010).
- Fonds monétaire international, déclaration de censure de l'Argentine (février 2013, levée en novembre 2016) — première censure de l'histoire du FMI pour données d'inflation et de PIB mensongères.
- Alberto Cavallo & Roberto Rigobon, « The Billion Prices Project: Using Online Prices for Measurement and Research », Journal of Economic Perspectives (2016) — la mesure de l'inflation par les prix en ligne, née du cas argentin.
- The Economist, « Keqiang ker-ching » (décembre 2010) — le câble diplomatique de 2007 (via WikiLeaks) où Li Keqiang qualifie le PIB provincial de « fabriqué par l'homme » et lui préfère électricité, fret ferroviaire et crédit.
- Données des figures : Bureau of Economic Analysis (PIB, série A191RL1Q225SBEA) et Bureau of Labor Statistics (emploi, série PAYEMS), millésimes successifs via ALFRED/FRED, Federal Reserve Bank of St. Louis ; calendrier et triangle stylisés d'après les calendriers de publication officiels.